In my previous article, I talked about my attempts to improve the performance of the Untold Engine. Even after adding GPU frustum culling to reduce the CPU workload, the engine was still CPU-bound — stuck at around 26.7 ms per frame.
Profiling with Xcode Instruments pointed the finger at Metal’s encoder preparation, which appeared to take ~15 ms. Based on that, my next move seemed obvious: switch to a bindless rendering.
What does that mean? Instead of rebinding textures and material properties for every draw call, I would move everything into a single argument buffer. Each draw would reference materials by index. In theory, this should drastically cut CPU overhead and pair nicely with GPU-driven culling.
But reality didn’t match theory. After spending days moving to a bindless model, I ran the engine with 500 models — and the performance needle didn’t budge. In fact, things got worse: encoder prep time increased from ~15 ms to ~17 ms.
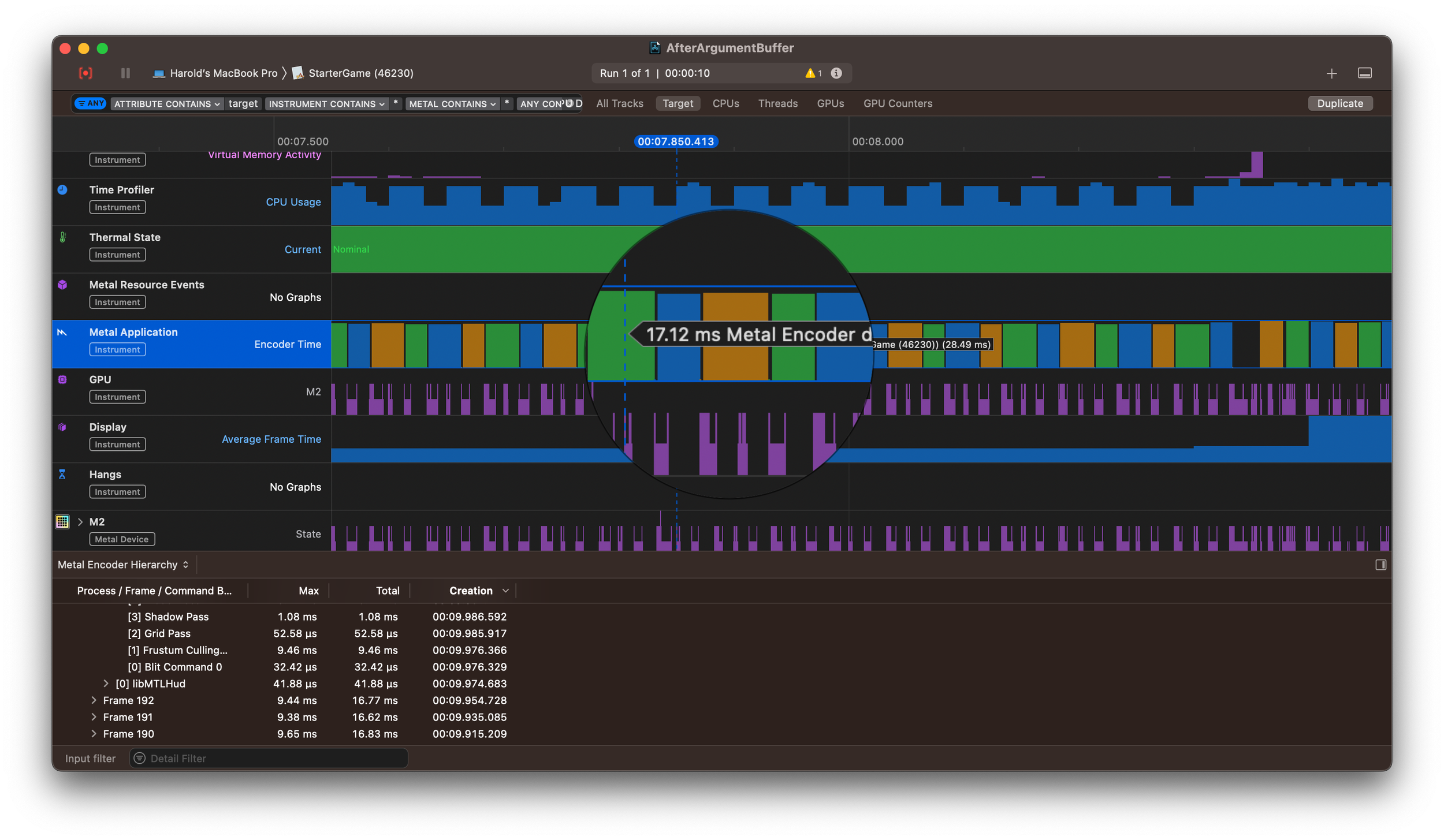
You can imagine my disappointment. But I kept digging. And then I found the real bottleneck. Instruments showed the CPU was spending almost 9.5 ms just preparing data for GPU frustum culling.
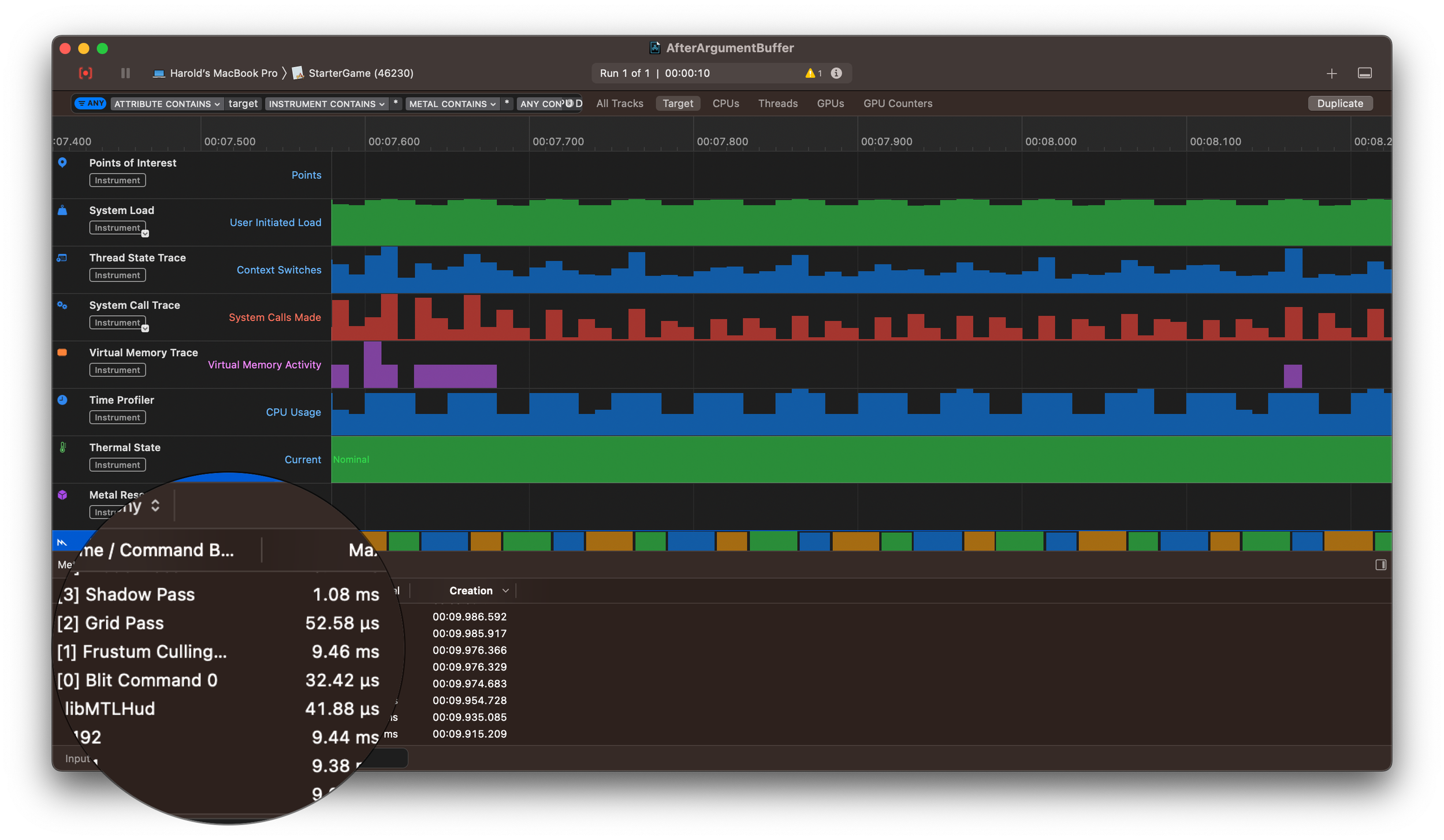
So the encoder wasn’t the problem after all. As I dug into the code, I discovered the true culprit: a single function that queries all entities with specific component IDs.
Here’s what was happening:
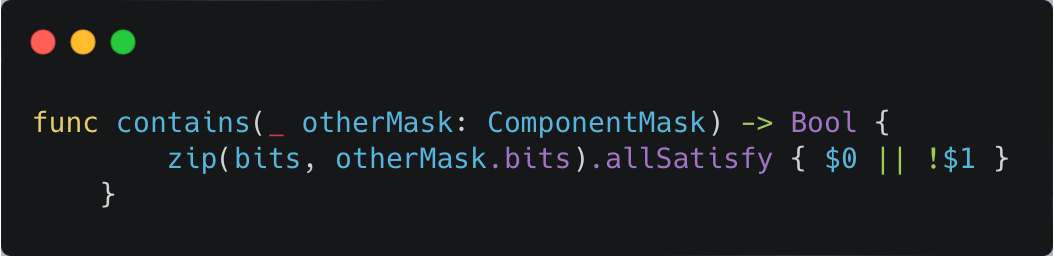
👉 My component mask was stored as an array of 64 booleans. Every time I checked an entity, the code looped through all 64 slots, read from two arrays, and branched on each one. With 500 entities, that meant tens of thousands of tiny checks every single frame. No wonder the CPU was choking.
The fix? Replace the boolean array with a single 64-bit integer and use a bitwise AND. That collapses the entire check into just two instructions. Here’s the new function:

That one change dropped the CPU frame time from 26.7 ms down to 16.7 ms. The GPU frame time sits at 9.3 ms.
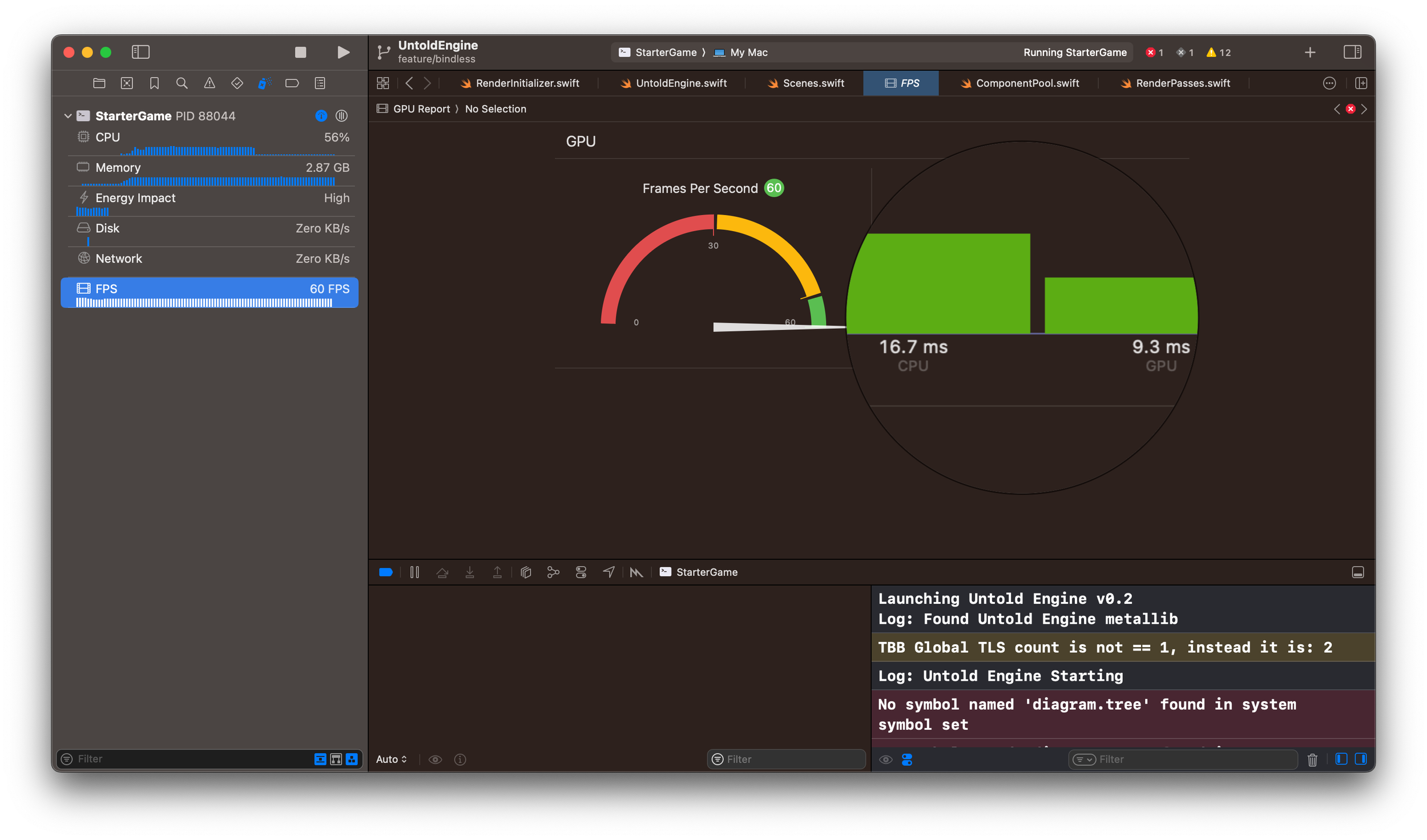
In other words, the engine now runs at a solid 60 fps.

I’m happy with the results: the engine is no longer CPU-bound or GPU-bound.
But I’m not done yet. The next step is implementing occlusion culling — and I’m excited to see how far I can push performance.
Thanks for reading.
